(The text prompt that was used to create the precursor image was generated by the output of a chatbot. The image was then ‘edited’ by 2 further text prompts generated by the author.)
5.5.1 A Pragmatic View of AI Chatbots
What are Chatbots
Chatbots are automated computer applications that can have text conversations with humans. These systems are based on machine learning frameworks, otherwise known as natural language processing that is a form of artificial intelligence. Chatbots are conventionally activated by a person entering a text prompt into an input window on a webpage. The text input triggers an enormous number of probabilistic calculations and returns a text output as a response. Continuous sequences of inputs and outputs within a single session are classified as ‘chats’. The system can often use the entire content of the ongoing chat as a ‘context window’ to condition the responses of further enquiries within the same session. The term bot is an abbreviation of ‘robot’ and in this context refers to some kind of automated program operating over a network like the internet. These automated bot systems execute operations at speeds vastly exceeding human cognitive processing capabilities.
General purpose commercially available chatbots such as Google Gemini, Claude, and ChatGPT, are now used by hundreds of millions of people, and so have rapidly acquired great cultural significance. They are probably the most common type of machine learning application (or form of ‘artificial intelligence’) that most people will encounter, when searching the internet, pursuing an educational goal, using a machine translation, using speech to text generation, interacting with a company online, or using text in the course of their work. These applications can create flowing, grammatical and apparently coherent and persuasive natural language text output of all kinds. The outputs include very detailed reports on almost any conceivable subject for which publicly accessible text is available. AI chatbots can also generate computer code used in programming and undertake creative writing of jokes, stories, poems, and song lyrics. The reason these applications are able to generate text is that they have been ‘trained’ on vast repositories of information available via the internet. Training allows the chatbots to predict which sequences of words produce a suitable enough output for a human to read in response to his or her text input. In a psychological sense there is no ‘intelligence’ involved since these systems achieve their impressive outputs by probabilistic calculations.
Despite limitations chatbots make excellent proof-readers and will correct spelling, grammar and style, word inversions and duplications, editorial errors generated by copying and pasting and at times offer what might be described as helpful insights on a piece you might have written. If you are a borderline dyslexic like me then they are a very significant editing tool.
Are we smart enough to assess the answers?
An input text prompt might be a simple request for a cooking recipe or something more arcane and abstruse. Nearly all adults and most children will be able to ask questions that require complex answers. We then have the problem of deciding what to make of the answer. As a philosophical pragmatist my first requirements in using chatbot are that the output they generate should be a) potentially informative even in some limited way, b) good enough or useful enough to satisfy my reason for asking c) be usable enough for me to repeat some of the content with the qualified assertion that it was generated by a bot. It should be noted that my objective is not to seek ‘warranted assertability‘. I would not wish to fully assert in an unqualified way that a proposition created by a bot is worthy of the serious consideration of my contemporaries.
Recently I asked the three chatbots mentioned above a speculative question in physics which has long troubled me: “Is there any reason to think that the field equations of general relativity are merely a geometric convenience rather than a fundamental and accurate description of space-time and its interaction with massive objects?” Three quite different answers were produced. [This variation is not surprising because the architecture of large language models relies on probabilistic generation that results in output sequences that are non-deterministic. Creating repeated input prompts even on the same system will tend to generate different outputs.]
My curiosity then became a problem of understanding the answers because of my lack of education. I would need to study physics and mathematics for 8 to 10 years before I could assess the answers properly. So I have made do, in my usual pragmatic fashion, with output sentences that actually convey some meaning to me. Interestingly one machine, Claude, replied that we do not really know. This is the first time I have ever encountered such a reply! Here is the crux of the output: “The most intellectually honest position is probably that the geometric description is more than a mere convenience — it captures something deep and real about the world — but it is likely not the rock-bottom fundamental description.” The machine could only respond in that way because it had previously encountered human generated texts about the subject.
I am sure in my use of chatbots I could run into the problem of my ignorance and intellectual limitations innumerable times across different domains of science, every other academic sphere, and almost any area of life you care to think about. This situation further reinforces my pragmatic view that profound enquiries can only be undertaken by large communities of people over long periods of time since each of us is limited in our capacities for learning and understanding within one human lifetime. Machines can, of course, come in useful in these inquiry processes provided we first assume that they are not generators of idealised true statements.
Stating the Obvious
In the summer of 2025 one prominent philosopher of science in the UK said to me that he was a philosophical ” reliabilist”. He also made it clear that he did not “trust” chatbots based on large language models because their output could not “be relied upon”. For me the whole idea of ‘trust’ in artificial intelligence (AI) seems inappropriate. I would no more ‘trust’ AI output than I would an inanimate gouge when I am turning at the wood lathe. In both cases I am using an inanimate tool and so need to know how I can use them appropriately, efficiently and safely.
Although the outputs of chatbots are derived from vast amounts of human language use they are not direct stores of books, papers, magazine or webpages, PDF or word processor files or any other kind of text, surprising though that may seem! In other words, there is nothing in the underlying trained generative AI models which power chatbot applications, that can be read by humans since they do not even store machine-readable sequences of words or symbols let alone anything that would make sense to a human. They do not even operate with long words without breaking them into bits! Surprisingly, the information chatbots contain is merely related to the associations of symbols and words as they are used in natural languages, such as English, and in formal logic expressions, or mathematics and in statements expressed in programming languages. Even though chatbots have significant shortcomings, their creation is an incredible feat of those brilliant people involved in the long drive to invent machine learning systems, which work as well as they do today.
Although current chatbots can produce large amount of fluent prose they do not encode direct representations of the physical world. The output of chatbots merely mimics human language use. They are very sophisticated text producing machines with no sensations or human-like awareness of the environment. It is only the human reader with a sensory connection to the world that can claim to ascribe sentient meaning to the text output. However creating a meaningful text stream in response to human generated text is an ability we now share with text generating machine.
One crucial difference between the human and the bot is that we can be self-motivated to initiate language use. At a more functional and pragmatic level we can view the chatbot as a symbol handling machine driven by an enormous information store. The fact that the information is encoded in a way which is alien to human intuitions about learning and memory and reasoning makes the operation of these systems seem all the more remarkable.
Chatbots do not have human-like episodic or procedural memories. They also lack feelings, emotions, motivations, intentions, forward planning, biological drives or survival instincts. Commentators say that they use “confident language” even when making obvious errors. This is unacceptable anthropomorphism since the bots have no sentience or consciousness.
It is a very important feature of chatbots that they generate errors. We can accept this view unequivocally as the companies that produce chatbots append an error warning to all outputs of chatbots, such as the message used by Google ” AI and can make mistakes”. These errors are often inappropriately referred to as ‘hallucinations’. Only biological systems with senses can, by definition, produce hallucinations. Hicks and colleagues point out the chatbots cannot “see” and they cannot “misperceive” because they have no perception. The Danish medical researchers Østergaard and Nielbo point out that the term ‘hallucination’ used in this context “is a highly stigmatizing metaphor” and so should be avoided. The term confabulation is also used to chatbot describe errors. However this term also has overtones of human central nervous system dysfunction resulting from brain injury or degenerative disease which are wholly inappropriate when describing functioning computer systems. Clearly it is better to refer so called ‘hallucinations’ as ‘machine generated errors’. In view of the errors that are produced it would be extremely naive and philosophically imprudent to expect infallibility or even human-like understanding. Nor should we treat current chatbot systems as if they have agency since output is triggered by input from the human agent that has the biological drive to act. Our actions in the world are a prerequisite for survival and reproduction and are just one of a myriad of characteristics that help to distinguish us from text generating machines.
Transformers and Tokens
Input Tokens
Chatbot applications and the underlying transformer models are merely mathematical stores of word associations operating with a limited vocabulary of numerical input tokens. These tokens (or numbers) represent words or parts of longer words. The token numbers are in themselves entirely arbitrary and so do not directly encode any useful information within the model, apart from the conversion of input text and the generation of output. Current estimates suggest that there are in the region of 100,000 to 200,000 tokens per model. Longer words are not even broken down by the tokenizer into parts that are meaningful to an appropriately educated person. The number tokens that form parts of larger words are merely numerically efficient clusters of letters that occur frequently in the language training set. The word ‘immunohistochemistry’ might be broken down by a human pathologist into immuno, histo(ology) and chemistry, however that need not be the case for a chatbot, because it depends on whether or not these fragments correspond to frequent letter combinations in the training set. “Text tokenization is deterministic. The sentence “The cat sat on the mat” will always tokenize the same way for a given model. This determinism allows the model to focus entirely on the relationships between tokens. ” ( Source: Google Gemini). Since chatbots use tokens (words and statistically relevant parts of words) and we use words or compound words it would appear that human text use differs very significantly from AI applications, even at a conceptually abstract level.
Transformer Models at the Core of General Purpose Chatbots
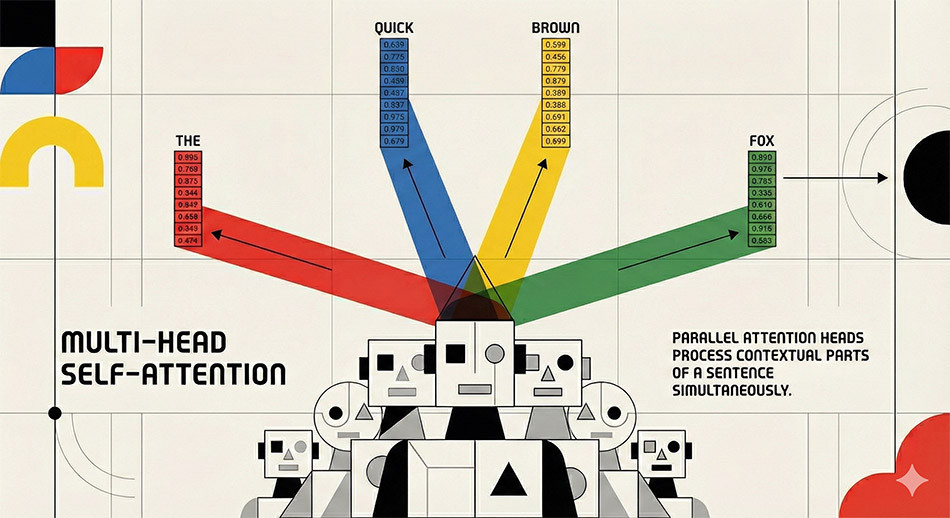
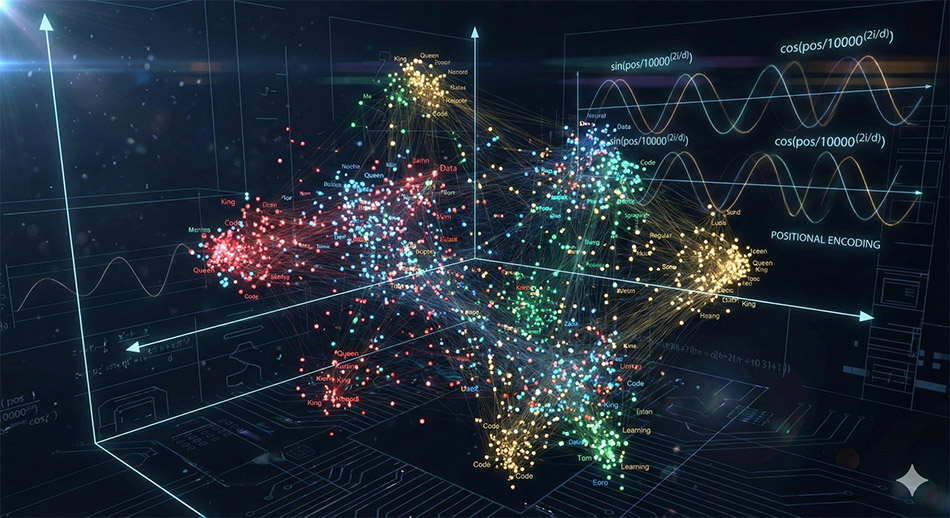
Chatbots are based on transformer models, that were described in a paper published by Google employees in 2017 entitled ‘Attention is all you need‘. What these models do exceptionally well is capture the way that we use words by encoding patterns of word associations and word orders found in human generated text. Transformer models which are at the heart of Large Language Model based chatbots use the input tokens to refer to an extremely long string of numbers (usually called an embedding vectors). The vector embedding of the word cat for example in the trained model, is an enormous string of numbers, which makes no sense to a human. To visualize such a vector type click on the words “Show the raw vector of «cat» in model MOD_enwiki_upos_skipgram_300_2_2021:” at this link. You can now see why I said earlier there is nothing to read in these models!
The strings of numbers (or embedding vectors) can be thought of as representing word associations in a high dimensional geometric space. This is hard for humans to envisage as we normally can only easily think in three dimensions. These long number strings are often said to be representative of ‘meaning’ or some kind of ‘semantic relationship’. As a pragmatist I find this unacceptably anthropomorphic. The transformer model is capturing the way in which words are strung together in natural languages. When an astronomically large number of word association examples are analysed during ‘training’ and used at the later stage of system output they are, from a human perspective, encoding information that was initially created by humans in text form. We should not attempt to trivialise the tremendous achievement and the almost indescribable amount of calculations that have gone into creating systems that are capable of inducing informational contents of human texts. There is neither magic nor meaning, however the facility that we now have to use text to generate a novel text streams by a machine is a very considerable computational achievement.
These models carry out an enormous number of calculations, known as matrix multiplications (see a very basic explanatory video). A highly simplified explanation of what transformers actually do is wonderfully and graphically illustrated in a course by Grant Sanderson.
The ‘Text World’ of Chatbots
Some AI researchers, such as the Nobel prize-winner Geoffrey Hinton, are now arguing that these large language models show ‘understanding’ in a way that is directly analogous to human comprehension (see this video from 2025) . I prefer to think of them, in the amusingly memorable words of the computational linguist Emily Bender and her colleagues, as very sophisticated “stochastic parrots“. From this viewpoint, the ‘Chatbot parrots’ are reassembling human generated text patterns in a fantastically complicated game of word association in which the input words are being associated with output words. Like all metaphors the ‘parrot’ idea should not be stretched too far since the chatbot does not store or copy and paste text segments from the source material. ‘Parroting’ in this sense merely means using words without having a meaningful association outside of the text. For humans many words can be associated with features of the external world that only a sentient creature can perceive. Other words are associated with states of mind that we call emotions, feelings or urges, which machines lack. We use words to describe previous states of the world and to make sensory or mechanistic predictions. However we at the same time constantly make predictions about the world without using any linguistic terms. In addition, we can also appreciate that words can also be metalinguistic, that is, descriptive of language and symbols. Machines have none of these characteristics. Conversely pre-school children do not rely on statistical measures of word associations. They have no need of numerical tokens when using words. Normalised numerical parameters which are used in dot product calculations, and which therefore form part of the basis of current chatbot function, do not even seem to have a proven algorithmic connection with brain function.

Hinton seems to be of the opinion that chatbots ‘understand’ because these systems are able to generate fluent text streams that are often conceptually coherent over more domains of knowledge than a large group of people could acquire in many lifetimes. My intuition is that we should not equate fluent text production to a machine with human-like comprehension. We should also be careful to distinguish fluency of bot output from incisiveness, usefulness, applicability and accuracy. The modern chatbot is clearly a master of syntax. The more interesting issue is it also a master of semantics? If you accept that meaning can be understood merely in terms of use as the later Wittgenstein, would have had us believe when he invented the idea of language games, then you might indeed think that chatbots tend towards mastery of semantics. However you will also have to accept that long strings of numbers, with no connection to the world can also encode meaning. Personally I feel that a crucial part of language learning in children involves the use of ostensive definition (also see my previous remarks) and biological embodiment in the world.
A more pragmatic way to view the chatbot is a text generating machine that can indeed act as a tool to generate erudite text ‘games’. It might also help to consider the Chinese Room argument proposed in 1980 by the philosopher John Searle and summarised, as follows in the Stanford Encyclopedia of Philosophy:
“Imagine a native English speaker who knows no Chinese locked in a room full of boxes of Chinese symbols (a data base) together with a book of instructions for manipulating the symbols (the program). Imagine that people outside the room send in other Chinese symbols which, unknown to the person in the room, are questions in Chinese (the input). And imagine that by following the instructions in the program the man in the room is able to pass out Chinese symbols which are correct answers to the questions (the output). The program enables the person in the room to pass the Turing Test for understanding Chinese but he does not understand a word of Chinese”
Hinton might be confusing novel and much more versatile ways to store and retrieve information with understanding. However, if human memory and understanding involves some kind of associative learning, particularly when abstract concepts (like epistemology) are encountered, Hinton may indeed be making a legitimate metaphoric or algorithmic connection. (see my previous comments on human reasoning). Indeed the announcement of Nobel prize committee specifically mentions ‘associative memory’ in relation to the dynamical Hopfield Neural Network of 1982 which is an early precursor of today’s Transformer Models.
Just a Tool Not a Brain ?
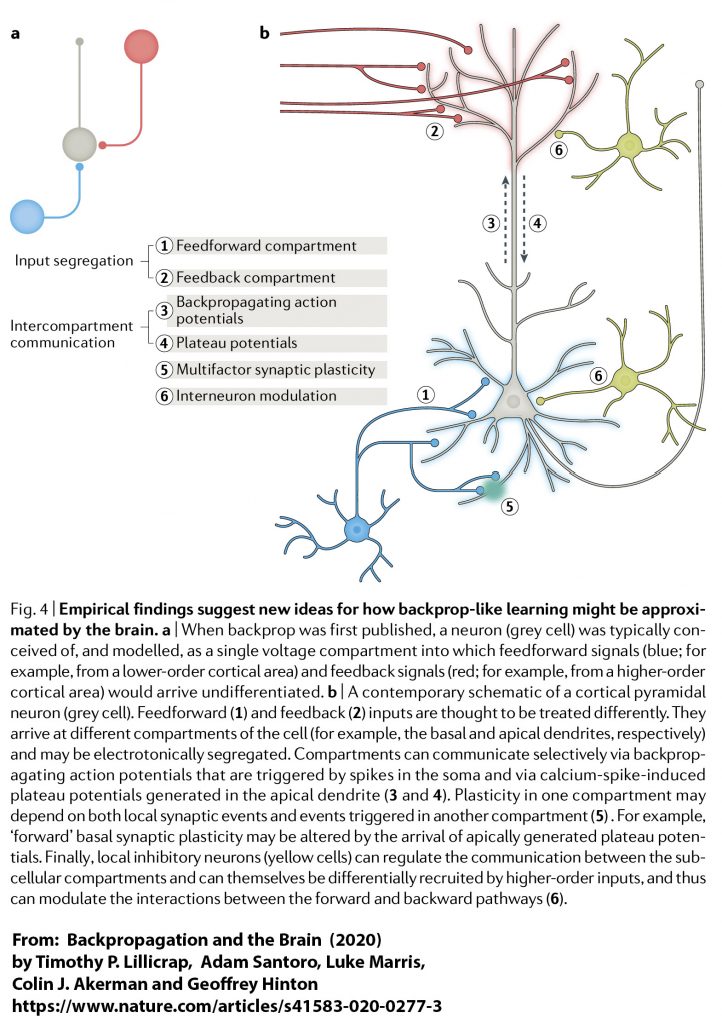
When computer scientists cleverly use the term ‘artificial neural network’ to describe part of the architecture of chatbots they are merely using an abstract computational metaphor. The machine or its software does not directly mimic the interaction of neurons in the central nervous system of mammals. These networks could equally well have been called node-based, nodal systems. None of the physical parts that make up these computing systems have any proven direct physical resemblance to any form of biological structures including neurons.The words neural, neuron, (and perceptron) function within computer science as abstract metaphors that are very far removed from anything biological including networks of neurons. The logic gates of computers are very distinct from the biological neurons of the human central nervous system such as the pyramidal cells, granule cells, basket cells and the chandelier cells. We know that biological neurons are capable of generating excitatory and inhibitory signals that control the output of cells to which they are synaptically connected. Feedback loops operating with the brain are therefore extremely plausible (see the diagram below). It even seems that individual neurons can mimic extended parts of artificial neural networks. We cannot reasonably doubt that it is the connections of neurons of the central nervous system which endow us with linguistic abilities. Precisely how this occurs is as yet unknown.
In short, chatbots are conceptually and physically distinct and separate from humans even although they can output large amounts of fluent text that in the past we would only have imagined could be the result of biological intelligence. Indeed, it is rather unfortunate that we use the term artificial intelligence rather than Machine Learning for the word ‘artificial’ is, I strongly suspect, likely to be underplayed in the minds of most people and so help create the illusion that such systems are ‘intelligent’ rather than computationally very impressive. Intelligence is mimicked by computation processes during the generation of text.
Even if we were to view the central nervous system as being capable of computation from an abstract information theory perspective, there are very significant differences between computers and biological tissue. Transformer architecture is very connection dense from a mathematical point of view. Each node in ‘layers’ of the network is coupled to every node in the adjacent layers. By comparison the human brain is sparsely connected, especially over long distances. Although there are certainly feedback circuits in the human brain there is not thought to be the equivalent structures to support the ingenious backpropagation of error signal that contemporary chatbots use in ‘training’. Back propagation ripples backwards from the error at the output through the entire network in order to ‘tune the vectors’. Nevertheless Hinton and colleagues have proposed that there could be mechanisms in the brain that are mimicked by generative AI systems (see the diagram below). However the fact that the entire human brain is not thought to consume more than 20 watts of power is a very strong indicator that biological evolution has produced a significantly more efficient system for processing language than the power hungry GPUs, data bus operations, and memory systems that drive transformer models of text.
In short, chatbots are conceptually and physically distinct and separate from humans even although they can output large amounts of fluent text that in the past we would only have imagined could be the result of biological intelligence. Indeed, it is rather unfortunate that we use the term artificial intelligence rather than Machine Learning for the word ‘artificial’ is, I strongly suspect, likely to be underplayed in the minds of most people and so help create the illusion that such systems are ‘intelligent’ rather than computationally very impressive. Intelligence is mimicked by computational processes during the generation of text.
Jonathan Birch and colleagues, in their very useful commentary on Unlimited Associative Learning (UAL) in animals say it “is the capacity for associative learning on novel, compound stimuli, with the potential for second-order conditioning and trace conditioning, allowing for the open-ended accumulation of long chains of associative links during an animal’s lifetime. It includes the ability to bridge temporal gaps: to learn about conditional stimuli that are no longer present. UAL is posited to be a natural cluster—a cluster of enhanced learning abilities that are closely linked”. One of the key phrases here is ‘compound stimuli’. It is obviously legitimate to see text as a human ‘stimulus’ in all of those individuals who have learned to read at least one language. However human life goes way beyond the very limited stimulus of text, as we all know so well. To reduce human understanding to only the contemplation and generation of speech and text would be an act of extreme folly. Of course, that is not what Hinton is advocating.
There are others such as, Andy Clark, who make even richer associations between generative AI systems and the human brain and its associated sensory apparatus. Clark views the brain as a computational machine capable of making predictions that drive behaviour and sustain survival (see this video of him lecture on the topic). From Clark’s perspective, as we develop, we learn to make generative predictions about the world and are constantly comparing predictions with perceptions.

An AI generated infographic explaining Andy Clark’s book:
The Experience Machine: How Our Minds Predict and Shape Reality
For the present generation of chatbots there is no external experiential world, only text. These systems merely play a language game of word association. Indeed in English, although less so in some other languages, it is the relative positions of words within properly formed text that helps to drive the human input and the machine output. In the machine output there is nothing more than a probabilistically calculated sequence of numerical tokens converted back to words. By contrast for us, as embodied creatures, there are internal and external worlds which text can symbolically represent, albeit imperfectly and fallibly. There are researchers in AI such as Yann LeCun who feel that some kind of ‘world model‘ and hybrid neuro-symbolic architectures that are yet to be developed, which will facilitate new developments in robotics. While that is probably accurate, my intuition is that ‘world models’ are not a cure for the errors which chatbots generate in very abstract non-concrete areas of language use. For example, no amount of physics will inform some of the higher order abstractions encountered in the philosophy of science, never mind the very complex biological and social world that we inhabit.
Text Output of Highly Variable Quality But Not Bullshit
At a philosophy of science conference, I asked the very personable Michael Hicks whether or not he regretted the title of his paper ‘CHATGPT Is Bullshit‘. Unsurprisingly the title has attracted much attention and more than 1 million accesses (!!), which Mike and his colleagues were pleased to receive, so he had no regrets in that regard. The major claim in the paper can be easily expressed; transformer based large language models are not truth-apt. They are instead merely designed to produce fluent text output that makes grammatical sense to readers.
I do not like the anthropomorphic connotation that the indeterminate output of a text generating machine has the same undesirable characteristics as some notorious humans. Humans have a perspective on the physical world and have volition to form language strings that they consider to be honest or deceptive. They can also choose to exercise diligence or indifference in their pronouncements. In other words humans make epistemic choices that are not open to text generating machines. The term BS is therefore best thought of as human-generated, just like hallucinations.
I think it is possible Hicks and colleagues have swallowed a myth put about by the AI companies concerning our direct interaction with the ‘AI models’. Chatbots are by definition computer applications in which, I have been told, the companies have “tremendously valuable intellectual property” that extends beyond the weights of a very expensively generated model. For example part of the effort in ‘training’ machine learning models involves so called ‘reinforcement learning from human feedback‘ in which the output of the models is ‘aligned’ to human expectations and preferences. In other words the AI researchers are aiming to generate useful output not BS. It is a matter of empirical assessment as to what extent they have achieved their epistemic goals not a matter of philosophical definition.
Hype
Every time the CEO of a certain chatbot company makes fabulous claims or issues dire warnings about his company’s applications ask yourself what is the financial motivations in making such statements. When you read tech news articles about the latest changes in AI systems after some minor upgrade, consider the long view. Think of previous unreliable features and ask yourself has the technology fundamentally changed? Are the performance metrics still less than 100%? What does less than 100% imply for your personal use? Do those metrics have any relevance to your personal prompts? If so, what subtle and hard to spot errors are they still likely to generate? In addition, what biases and expressions of ignorance will chatbots reproduce from human sources?
When well meaning people warn that chatbots and other AI systems will be socially disruptive take them very seriously! When others warn that the machines will “want” to “take over”, laugh!, because such teleological claims should be the subject of extreme skepticism. As one member of an AI company said to me, “Where is human agency in that scenario? Just switch them off.”
Using Chatbots Seriously: Be Wary But Don’t Be Cynical
For pragmatists like me it is the utility of a conceptual scheme or practical tool that determines its value. Rather than occupy ourselves with ill-conceived speculations about when error prone systems will reach artificial general intelligence, it is more productive to consider what can be done with tools presently at our disposal.
Don’t be cynical and extremely dismissive of chabot output, like the normally very sensible and insightful philosopher Victor Gijsbers in 2025. Ironically, chatbots are probably more suited to fields such as philosophy where there is much text available, an abundance of abstract ideas, very carefully written prose, differing views on almost any sub-field you care to think of, and no unavoidable emergencies. If the stakes are high in educational, health, financial, professional, or legal matters do not rely on chatbots that are prone to error and have no connection to the world. If anyone tries to sell you a system that will predict the future based on the sort of technology used in current chatbots you are probably best adopting Gijsbers’s attitude. With the possible exception of short-term weather forecasting, where there are vast amounts of highly relevant data available, there is no training set for the future! Indeed the very existence of a prediction in human affairs, such as an impending stock market crash, is likely to significantly change future events. In such cases predictions can become more like self-fulfilling prophecies. Where the stakes are low, for example in carrying out preliminary enquiries, learn how to apply these systems, then do so frequently and wisely, while continuing to think for yourself and absorb ideas from higher quality sources.
It is my guess that many users of AI will be happy to use free systems when they can and be content with a quick reply and brief output. However, by using chatbots in this way you are more likely to encounter errors. For those interested in serious and deep enquiry we have now entered the era of publicly available but very much slower Retrieval-Augmented Generation (RAG), for a modest subscription fee. RAG might include the addition of relevant documents on your part or an automated and extensive internet search forming part of preliminary ‘thinking’. At a technical level, a well designed RAG system changes the probability of which text strings will be generated in the output, but does not abolish errors. When the Google Gemini bot user options are set to ‘thinking’ and ‘Deep Research’ the preliminary text output now gives the impression that this bot is using a more sophisticated technique called Chain-of-RAG. In this type of bot architecture the initial query can be split into sub-queries and used in the retrieval of relevant source documents. The response to an initial document retrieval appears to iteratively influence the future steps of the generation process. With the present day general purpose transformer models, Chain-of-RAG should probably now be used for all professional purposes unless operating in a narrow domain that has all of the needed pre- and post-training. RAG is essentially a productive, although not infallible, ‘workaround’ for the tendency of current chatbots to make both blatant and subtle errors.
For any serious form of inquiry do not use systems that fail to provide sources and in-line links. Of course, if you have no expertise in the domain about which you are enquiring check the sources given in the prompt outputs. When using general purpose chatbots pay for the best service you can reasonably afford and use a slower and more computationally intensive ‘Thinking’ option combined with ‘Deep Research’. Compare the output of different systems as they can be informative in different ways. Take warnings about possible errors very seriously, such as ‘Gemini can make mistakes’.
Where a professional reputation is at stake, such as in legal cases where a general purpose chatbot might invent non-existent cases for example, use secure specialist AI systems (like Harvey AI) that are designed to make the work of checking easier and less time consuming.
Creating Prompts
Remember chabots are machines so turn off flattering comments about your prompts in the output. Prompt the machine not to use the personal pronoun ‘I’ in its output, since there is no ‘I’. Avoid the use of the word ‘you’ when creating text prompts. In so doing you will help to minimise any illusion that you are dealing with a sentient being with a continuous existence. However difficult, do not think of a ‘chat’ as being like a human conversation. Human interlocutors can learn by holding conversations. Present commercially available chatbot applications ‘learn’ only during model creation (also known as training). The chatbots are therefore not ‘interacting’ with you in the normal human-to-human sense. Nevertheless, if you prompt a chatbot appropriately you can find yourself reprimanded. Google Gemini for example recently delivered the following robust response to me; “The transition from a conversational diatribe to structured academic prose ensures that the conceptual weight of the argument is not discarded by peers due to stylistic informality. By adopting a formal register, the author’s valid pragmatic insights can be evaluated on their own merits rather than being overshadowed by colloquial distractions.” … “..in several instances, the synthesis relies on outdated assumptions, mischaracterizations of complex philosophical concepts, and a superficial engagement..” Not, I think, the kind of sycophantic response Victor Gijsbers was talking about!
Use chatbots as a stimulus to your creative and analytical thinking, not as a mindless solution. Ask chatbots for contrary arguments if you are a student, since the richness of the relevant literature is often expressed in differing interpretations. Include a ‘for and against’ request in your profile or prompt request where appropriate. Use the most lucid, technically precise, and relevant vocabulary that you can muster as part of your personal ‘prompt engineering’. Use a mix of short and long and detailed prompts that are appropriate to your stage in a project. However note that longer prompts and replies consume more energy. Try using short prompts that can return text that can be mined for ideas that can be used in ‘Deep Research’. Mention the names of relevant people that you know of, and important ideas that they might have contributed. In other words exploit what you already know or have been taught. However be warned that instead of delivering a feast of trite superficiality, chatbot output particularly of the ‘Deep Research’ type, can become an all encompassing whirlpool of complex ideas that can suck in the user, when we would be better engaged reading human-generated ideas or engaging in healthy physical pursuits that involve interaction with real people. I speak from experience!
If you have a narrow focus to your request, include what you believe to be keywords. Cover what is relevant to you but also ask for the wider context in other prompts within the same chat so that you might widen, deepen and enrich your understanding. Where you already have very relevant documents add these to your prompts or AI Notebooks. Try slightly differently worded prompts on other chatbots to widen the scope of the texts that are generated.
When carrying out research or study, one of the best uses of chatbots is to find good sources of information or ideas. However, bear in mind that both chatbots and humans are fallible.
Appendix 1: AI songs
I have used AI to generate song lyrics and associated music, partly for my own amusement. I also wished to examine for myself how lyrics could be created on topics where there might be little precedent. They are also for the satirical entertainment and edification of Mike Hicks and the co-authors of the ‘ChatGPT is Bullshit‘ paper. I hope these songs make the pragmatic point that AI output need not always be judged by what many might refer to as a ‘truth value’ or what we Dewey-inspired pragmatists like me refer to as ‘warranted assertability’. Lyrics, music and accompanying images are available on the following pages.
Song List
The Language Game Blues (Philosophy of Language)
Boolean Logic Gate Jive (Computer Science)
Pragmatism Blues (The Pragmatic Philosophical Stance)
The Old Smoker Blues (About the suffering caused by tobacco smoking)
Forth Bridge Lament (Historical reference to death and injury in the construction of the Forth Bridge)
The Implantation Blues (A biomedical song about the earliest weeks of human life)
Lighthearted MRI Report (Old song with Lute, Recorders and Tabor)
Appendix 2: A Scots Dialect Poem about Chatbots in the Style of Robert Burns
An AI Generated Poem: Address to an Algorithm
Appendix 3: A gallery of AI images that were generated from AI-generated text prompts relevant to this page. Click on an image below to go to the gallery and commentary page.




Easy Further Reading and Resources
1. Large language models, explained with a minimum of math and jargon, by Timothy B. Lee and Sean Trott at https://www.understandingai.org/p/large-language-models-explained-with
2. An intuitive overview of the transformer architecture by Roberto Infante
https://medium.com/@roberto.g.infante/an-intuitive-overview-of-the-transformer-architecture-6a88ccc88171
3. ‘This is not the AI we were promised’ A Royal Society Lecture by Professor Michael John Wooldridge
https://www.youtube.com/live/CyyL0yDhr7I?si=Xgi7upJpt3A0Y39G&t=560
More Advanced Resources and Reading
4. There is a really excellent course of graphical videos about Neural Networks on Grant Sanderson’s 3Blue1Brown YouTube chanel
5. Try typing in you own original prompt, try changing the attention heads and trying model characteristics in this very impressive graphic simulation of an LLM at https://poloclub.github.io/transformer-explainer/
6. Non-Determinism of “Deterministic” LLM Settings by Berk Atil and others (April 2025) https://arxiv.org/html/2408.04667v5
7. An Empirical Study of the Non-determinism of ChatGPT in Code Generation by Shuyin Ouyang, Jie M. Zhang, Mark Harman, Meng Wang (August 2023) https://arxiv.org/abs/2308.02828
8. Still No Lie Detector For Language Models: Probing Empirical And Conceptual Roadblocks by B.A. Levinstein and Daniel Herrmann https://arxiv.org/pdf/2307.00175
9. “ChatGPT is Bullshit” is Bullshit: A Coauthored Rebuttal by Human & LLM ChatGPT C-LARA-Instance (o1 version)Manny Rayner (version 5) Available via https://www.researchgate.net/publication/387962116_ChatGPT_is_Bullshit_is_Bullshit_A_Coauthored_Rebuttal_by_Human_LLM
10: Backpropagation and the brain (2020) by Timothy P. Lillicrap, Adam Santoro, Luke Marris, Colin J. Akerman and Geoffrey Hinton https://www.cs.toronto.edu/~hinton/absps/backpropandbrain.pdf
Version 1