5.5.3 A Pragmatic View of AI Chatbots: Part 3
The text prompt that was used to create the precursor image was generated by the output of a chatbot.
A Few Words About How Chatbots Work

Chatbots use a form of computing known as an artificial neural network. This is a “type of AI that learns to recognize patterns in data by figuring out relationships on its own, rather than being programmed with strict, explicit rules” (source Google Gemini). Older ‘expert systems‘ AIs, by contrast, were programmed using rules-based computer logic, and so were much less flexible and much narrower in scope than the huge modern network-based systems. For a beautiful non-technical explanation of different types of neural network, see ‘What Is a Neural Network (For Non-technical People)?‘ by Adman Steele.
Input Tokens
Chatbot applications and the underlying transformer models (described below) are merely mathematical stores of word associations operating with a limited vocabulary of numerical input tokens. These tokens (or numbers) represent small words or parts of longer words. The transformer has encoding layers to change natural language words into tokens and decode the final output tokens back into words. The token numbers are in themselves entirely arbitrary and so do not directly encode any useful information within the model, apart from the conversion of input text and the generation of output. Current estimates suggest that there are in the region of 100,000 to 200,000 tokens per model. Longer words are not even broken down by the tokenizer into parts that are meaningful to an appropriately educated person. The group of number tokens that form parts of larger words are merely numerically efficient clusters of letters that occur frequently in the language training set. The word ‘immunohistochemistry’ might be broken down by a human pathologist into ‘immuno’, ‘histo'(ology) and chemistry. However, that need not be the case for a chatbot because it depends on whether or not these fragments correspond to frequent letter combinations in the training set. “Text tokenization is deterministic. The sentence ‘The cat sat on the mat’ will always tokenize the same way for a given model. This determinism allows the model to focus entirely on the relationships between tokens.” (source: Google Gemini). Since chatbots use tokens (words and statistically relevant parts of words) and we humans use words or compound words, it would appear that human text use differs very significantly from AI applications, even at a conceptually abstract level. Put simply, even the fundamental way we handle language is different from chatbots.
The Transformer Model Architecture
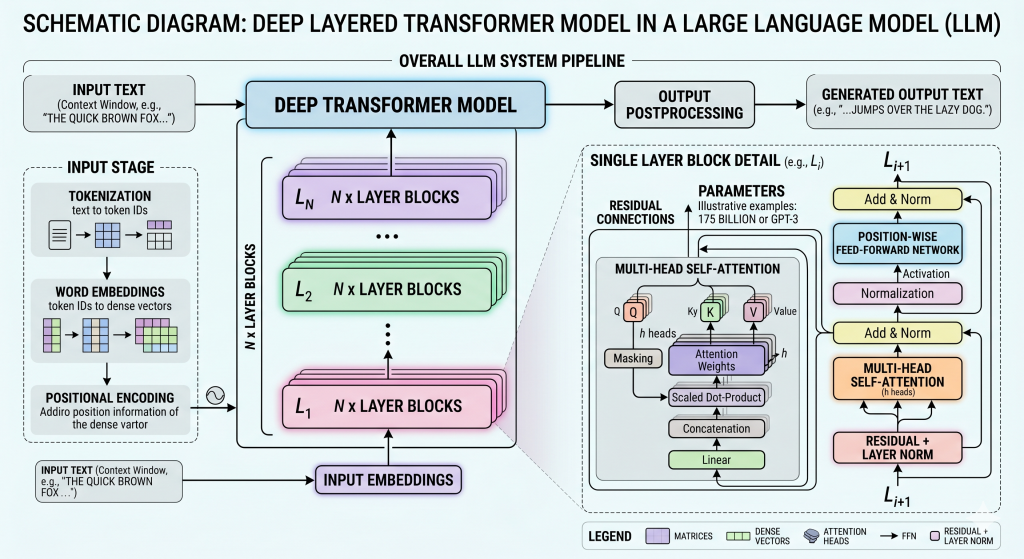
A nicely simplified schematic explanation of the transformer model architecture from the Cohere LLM University. See the associated clear article; What are transformer models?
(Cohere is a company that provides secure AI models and services to businesses)
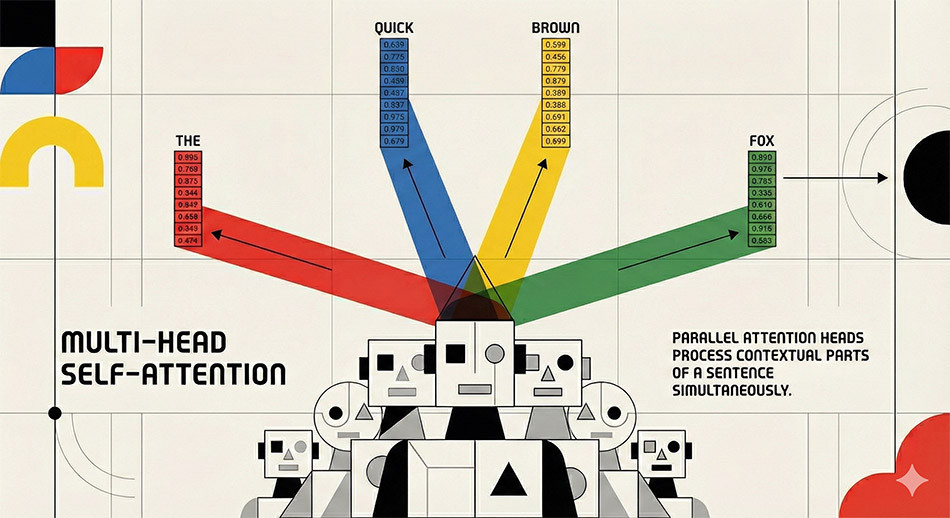
The multi-head transformer model is deliberately designed to pick up the statistical autocorrelations in well-formed human language usage. Consider the following sentence: ‘The words in this sentence only make sense because they have been used in a particular way, and in the case of English also because of the word order.’ For the final word ‘order’ to make sense, ‘word’ had to become before it, and so on. Such properties of word distributions are important within sentences and over much longer stretches of text. For example, one would expect the term ‘word order’ to appear in texts that deal with autocorrelation in language. The frequency of use and the distribution of those usages would also be expected to be different when compared to a book on the philosophy of science. Books by different authors also have different sentence sizes and different common word patterns that result in different autocorrelations. It seems utterly remarkable that capturing patterns of language use in this way can result in the creation of a machine that predicts text sequences, which have meaning for humans. This emergent characteristic is thought to become particularly successful as the model size, the amount of training text, and the amount of computation is increased. (see this easy-to-read source or a research paper by Google Deep Mind).
The very long strings of numbers (or embedding vectors) that encode English words (or more precisely tokens) can be thought of as representing word associations (or distances), in a high-dimensional geometric space. Google Gemini uses embedding vectors comprised of up to 3,072 numbers or dimensions. This is hard for humans to envisage, as we normally can only easily think in three dimensions. These long number strings encode the way words are used in a language, and are often said to be representative of ‘meaning’ or some kind of ‘semantic relationship’. As a pragmatist, I find this unacceptably anthropomorphic, since I do not equate the matrix multiplication of model computation with the nature of human thinking. The transformer model is capturing the way in which words are strung together in natural languages, but is not ‘thinking’ like a human. The model is capturing the syntax of a language, not the meaning of the words when they are used together in a properly formed sequence, i.e. the semantics. In more technical language, “A high-dimensional [embedding] vector provides a highly compressed, multidimensional map of a word’s historical use across a corpus [of text], but it lacks the capacity to bear a truth value. A vector matrix cannot be [logically] true or false; it can only be mathematically proximate or distant to another matrix. Therefore, from a philosophical standpoint, reducing semantics to high-dimensional geometry abandons the foundational requirement that language must possess representational fidelity” of the world. (source: Google Gemini Pro, Deep Research). In simpler terms, the transformer model is not undertaking the classic logical steps of “If-Then-Else” decisions or looping used in traditional programming on human defined parameters, where every path is predefined by the programmer. The original transformer design was engineered to produce text predictions on a probabilistic basis, not calculate an output based on defined pre-programmed steps.
The word ‘compute’ is now used in the AI industry to describe the stage of calculating the output from a given input. At the start of processing of the user’s input text, 2 types of vector are needed to mathematically encode the mathematical representation of the data. One is the embedding vector as described above. The other is the positional encoding of the token order in the input sequence. The embedding vector is then added to the position vector. The self-attention mechanism then uses that subsequent vector to calculate the pairwise relationship of words in the input text. Its primary function is to determine how much computational focus (or “attention”) a particular token in the input sequence should apply to every other token. To achieve the desired result, the transformer applies three separate mathematical transformations learned during the model’s training phase to produce three new matrices (normally referred to as K,Q,V) for each token. These are then used to calculate a score that specifies how relevant one word is to another, using both their embedding vector and the encoded position. The deep neural networks in commercially available transformer models that are in use today are speculated to be using more than 100 mathematically and densely interconnected layers (or blocks). The attention mechanism is a fundamental part of every repeating layer or block.
The type of automated calculation used by a transformer model is, known as matrix multiplication (If you wish to know about simple matrix multiplication, see a very basic explanatory video). In order to minimise the number of calculations needed, large networks are segmented into a Mixture of Experts.
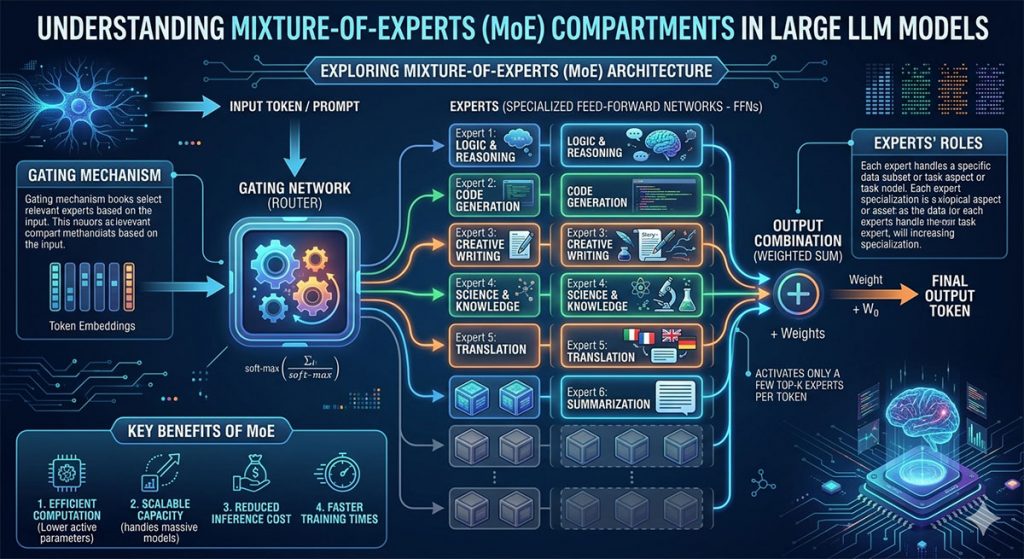
I am not sure to what extent the labeling of the experts in this graphic should be taken literally.
Learning
In creating huge foundational models, an astronomically large number of word association examples are analysed during the ‘training’ stage. The learned associations are later used in the inferential computational (or ‘compute’) stage of system output in response to text input prompts.
From a human perspective, the models are encoding information about word patterns in documents created by humans. The Large Language Models store hundreds of billions of weights (parameter values) needed to produce output on all the subjects encountered in publicly available text. Grant Sanderson has estimated that if you had a computer that could only do 1 billion arithmetic operations per second, it would take more than 100 million years to calculate a large language model. It has been estimated that training for a 1 trillion parameter compute-optimised model, 21.2 trillion tokens should be used! Calculation of that would model would require a mind-boggling 1.27×1026 floating point arithmetic operations (FLOPs)! In April 2026 DeepSeek-V4-pro model had 1.6 trillion parameters that used 33 trillion tokens in training. It also has a context window of 1 million tokens, which is enough for an enormously long chat that includes many retrieved documents.
The way that ‘learning’ is achieved during the training stage is by the ‘backpropagation‘ of error at the point of output. Backpropagation was invented by the Harvard Ph.D. student Paul Werbos and described in his 1980 paper ‘Backpropagation through time. What It Does and How to Do It‘. If the system predicts an output word (or technically a numerical token) that should not be there, it has created an error. That error is then used in the computationally intensive process of backpropagation to make improvements in the model. During training, the system starts with random values (or weights) in the vectors and recalculates the contribution of all the weights in the network to minimise next word prediction errors in the output. When that process is repeated billions or trillions of times, the network is trained. System-wide backpropagation is an arithmetically enormous process that does not correspond to any biological feature of the nervous system that we know about.
It seems extremely unlikely that biological evolution of multicellular animals over the past 500 million years has created a system that starts with random gibberish as output. It also seems equally improbable that we then retune the entire language capabilities of brain function for every error we make when learning. The Large Language Model, as previously stated, is trained on a corpus of human text containing trillions of tokens. By comparison, in learning a language, children perhaps encounter a few tens of millions of word instances.
Publicly available commercial chatbots need to be trained on extremely powerful computer systems. The processing chips are in some ways similar to the graphics cards used on the high-end domestic machines on which gamers play, minus the hardware needed to drive screen display and texture mapping. These systems are designed to carry out an absolutely enormous number of simple calculations simultaneously (or in parallel) at very high speed. They carry out low-precision (8-bit floating-point) arithmetic, at an unprecedented scale. Google said in 2026 that their ‘super-pods’ of 9,600 TPU 8t chips can calculate 121 exaFLOPs of compute (121 × 1018) floating-point operations per second (FLOPS) using and 2 petabytes of shared high bandwidth memory. That memory capacity is equivalent to 32,768 high-end home computers with 64 GB of RAM. By comparison, the world’s most powerful supercomputer computer, El Capitan at the Lawrence Livermore National Laboratory, can compute 1.809 exaFLOPs of high precision arithmetic.
We should not attempt to trivialise the tremendous achievement and the almost indescribable number of calculations that have gone into creating the AI systems that are capable of mimicking the informational content of human texts. However, the output is neither magic nor the outpourings of an oracle. Any meaning that the system seems to impart is one that we humans apply to the output. Nevertheless, the facility that we now have to use novel text streams generated a by a machine is a very considerable computational achievement.
Optimising the Output from In-Depth Inquiries
We have now entered the era of publicly available but very much slower Retrieval-Augmented Generation (RAG), for a modest subscription fee. RAG might include the addition of relevant documents by the user or an automated and extensive internet search forming part of preliminary ‘thinking’. At a technical level, a well-designed RAG system changes the probability of which text strings will be generated in the output, but does not abolish errors.
When the chatbot user options are set to ‘thinking’ the preliminary text output now uses more sophisticated techniques like Chain-of-RAG or Tree-of RAG. In this type of bot architecture, the initial query can be split into sub-queries. The initial responses iteratively influence the future steps of the generation process. With the present day general purpose transformer models, Chain of RAG or Tree of RAG should probably now be used for all professional purposes unless operating in a narrow domain that has all the needed pre- and post-training. RAG is essentially a productive, although not infallible, ‘workaround’ for the tendency of current chatbots to make both blatant and subtle errors. See this example of preliminary output created by an undisclosed RAG method created for me after I entered the following text prompt: ‘Describe computational irreducibility and its relationship to Stephen Wolfram’s Rule 30’. In particular, note the documents retrieved during the RAG process. Then compare the preliminary text with the final output in the ‘Deep Research’ report.
The more sophisticated systems are said to be Agenetic. An example of agentic workflow is the ‘Deep Research’ options in Google Gemini and ChatGPT (source Google Gemini). These systems act as AI-agents and are more flexible, as they can run inquiries autonomously and call the use of tools through an Application Programming Interface (API). When an AI-agent is incapable of determining the result, it can pause natural language processing and instead generate strictly formatted code that allows external communication through an interface to a tool, such as a web search or a programming interface. In this way, the system as a whole can generate and execute computer code and retrieve the results that have been generated by the external computational tool. When the results of the function call are received by the model, they are then incorporated into the natural language output of the Chatbot. The ability to solve unstructured problems and potentially self-correct are additional advantages of these automated systems.
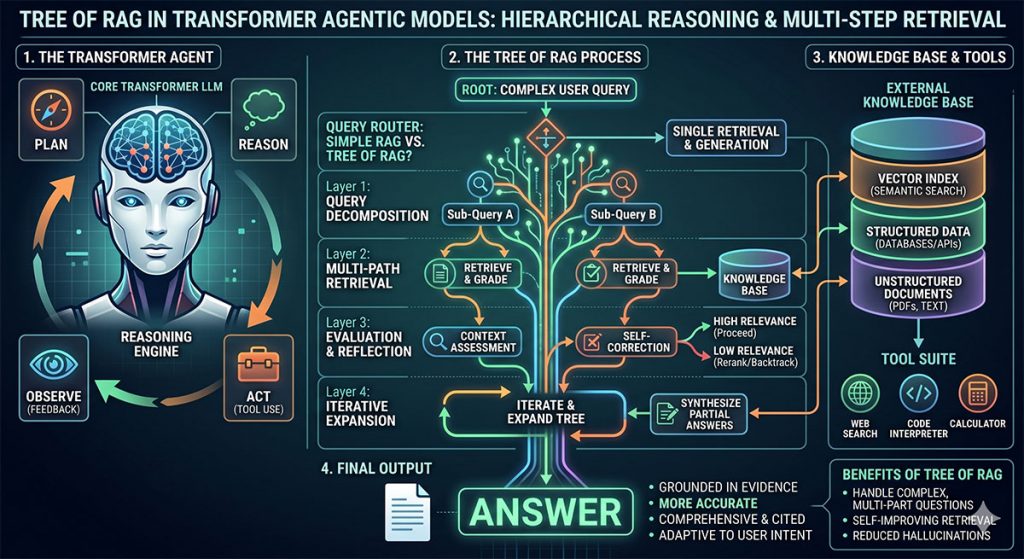
Treat the word reason with an appropriate degree of scepticism.
A Philosophical Question
Many important philosophical issues arise concerning the functioning of chatbots. The one that concerns me here is the fact that the AI companies are literally selling those agentic models as reasoning. We should ask ourselves is that reasoning in a human sense? Google Gemini, basing its response on human text, has produced the following response to that question:
“Without conscious understanding and intentionality, the AI is not reasoning; it is merely simulating reasoning … In computer science, “agentic reasoning” is a legitimate and accepted technical term used to describe a specific autonomous, iterative computational architecture. However, in philosophy, it is generally viewed as simulated reasoning.”
One problem, until recently, has been that the functioning of Transformer Models was said to be like a black box. However, a circuit tracing (or computational graph) approach has been developed by Anthropic, which helps to shed light on parts of the functioning. As a result, one commentator wisely warns, “even when language models appear to reason, they may be optimizing for surface plausibility rather than truth”.
Unless we subscribe to a doctrine of functionalism (in the Philosophy of mind), it seems wise to accept that reasoning requires conscious understanding, which agentic deep research chatbots do not possess. Although ‘reasoning’ might be an acceptable term of art for computer scientists, we should dismiss its use in ordinary speech, the same way as we reject the words confabulation and hallucination, as I have argued previously.
At some point in the not so distant future, that view will likely have to be revised when chatbots are re-engineered to introduce formal logic as used in ‘good old-fashioned AI systems’. For me, that is part of what it means to be a pragmatist. There are already new technical developments in AI that have the prospect of introducing continual learning, missing from present day chatbots. Improved learning might bring improvements in performance. Our views of chatbots will likely have to change.
Version 2.2
Easy Further Reading and Resources
1. Large language models, explained with a minimum of maths and jargon, by Timothy B. Lee and Sean Trott at https://www.understandingai.org/p/large-language-models-explained-with
2. An intuitive overview of the transformer architecture by Roberto Infante
https://medium.com/@roberto.g.infante/an-intuitive-overview-of-the-transformer-architecture-6a88ccc88171
3. See the 9 modules of Cohere LLM University.
https://cohere.com/llmu
4. ‘This is not the AI we were promised’ A Royal Society Lecture by Professor Michael John Wooldridge
https://www.youtube.com/live/CyyL0yDhr7I?si=Xgi7upJpt3A0Y39G&t=560
More Advanced Resources
4. There is a really excellent course of graphical videos about Neural Networks on Grant Sanderson’s 3Blue1Brown YouTube channel
5. Try typing in your own original prompt, try changing the attention heads and trying model characteristics in this very impressive graphic simulation of an LLM at https://poloclub.github.io/transformer-explainer/
RAG vs Fine-Tuning vs Prompt Engineering: Optimizing AI Models
A helpful video about agentic AI if you ignore the anthropomorphic language